最近看了DDIA,对于分布式共识算法很感兴趣,可以说共识算法是分布式的基石,而 Raft 算法又是共识算法中最简单的一个,Raft算法是一个专门用于管理日志复制的共识算法。共识(consensus)是大家关心的某件事情(比如选举、分布式锁、全局ID、数据复制等等)达成一致的过程及其算法。
Raft算法诞生与2013年,论文名字叫作《In Search of an Understandable Consensus Algorithm》,寻找一个更加容易理解的共识算法,从名字就能看出来,作者对 Paxos 的绝望。
复制状态机
在分布式系统中,为了提升高可用,一般使用基于副本的容错模型:复制状态机,复制状态机使用多个成员组成集群,成员之间数据完全一致(也称为副本),它可以保证即使在小部分(≤ (N-1)/2)节点故障的情况下,系统仍然能正常对外提供服务。
复制状态机一般和共识算法一起才能发挥作用,下面是一个典型的复制状态机架构。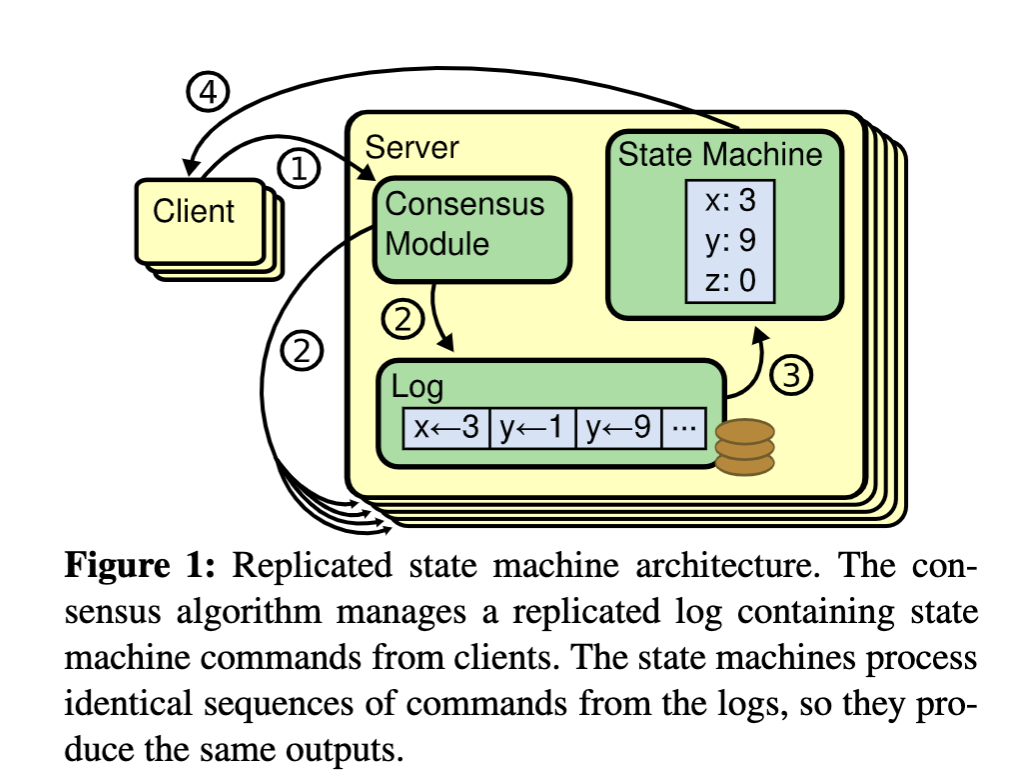
从图中我们可以清晰的看到:
- 第一步:客户端发起数据写入请求。
- 第二步:
共识模块负责将请求写入Log,以及将Log 复制到其他的Server。 - 第三步:将Log应用到状态机,由于每一个Server的Log中存储的命令序列是完全相同的,因此可以保证所有Server产生相同的结果。
- 第四步:状态机把结果返回给客户端。
Raft算法的核心
Raft算法通过选举机制确保每个任期(Term)中只有一个领导者(Leader),这个Strong Leader 负责处理客户端的请求和日志的复制。这样可以保证系统的高效性和一致性,避免了多个领导者引起的冲突,从而实现共识。
只有Leader才能接受来自Client的日志请求,Leader收到日志请求之后将日志写入到磁盘(无须咨询其他Server),然后将日志复制到其他Follower,这个过程是单向的。使用Leader/Follower模型可以大大简化日志复制的管理。
Raft算法的核心问题这三个核心问题是:
- Leader选举 (Leader Election)
- 日志复制(Log replication)
- 确定性(Safety)
最后一项确定性其实是前两个问题的约束条件,Raft算法在同一时刻有如下保证:
- Leader Append-Only:Leader日志单调递增,Leader永远不会覆盖或者删除自己日志里面的内容,永远只会新增内容
- Log Matching:日志匹配,如果两个server的日志包含了相同的Index和Term,那么在该index之前的所有条目都是相同的。
- Leader Completeness:Leader完整性,如果日志条目被提交到给定任期,那么该日志会被复制到更高任期的Leader上。
- State Machine Safety:状态机安全,如果Server已经确定给定Index出的日志条目已经应用到了状态机,那么其他Server一定不会知道该Index处应用不同的日志条目。
如何选出一个Leader?
Raft节点总共有三种状态:
- Leader :集群中只可能有一个Leader,Leader的作用是把Log复制到其他节点,周期性的向Follower发送心跳,维持统治。
- Follower:跟随者,只能被动接受日志,Follower超时之后自动变为Candidate开始竞选Leader。
- Candidate:竞选者,选举时间超时之后,Follower变为Candidate
其中Leader和Follower是持久状态,Candidate是一个中间状态,在选举时间超时之后Follower自动变为Candidate开始竞选Leader。
Raft 算法中,节点之间采用 RPC 进行通信,下面两种 RPC 是 Raft 基础功能的必要实现:
- RequestVote RPC:请求投票 RPC,候选人在选举期间发起,用于通知其他节点投票
- AppendEntries RPC:日志复制 RPC,由领导者发起,用于复制日志和提供心跳消息。
另外Raft中还有另外一个比较重要的概念:term 任期,每个term都由选举产生,每个Term都是一个单调递增的编号,每一轮选举都是一个Term周期,在一个Term中只能产生一个Leader ,每个node都存储了当前term的编号。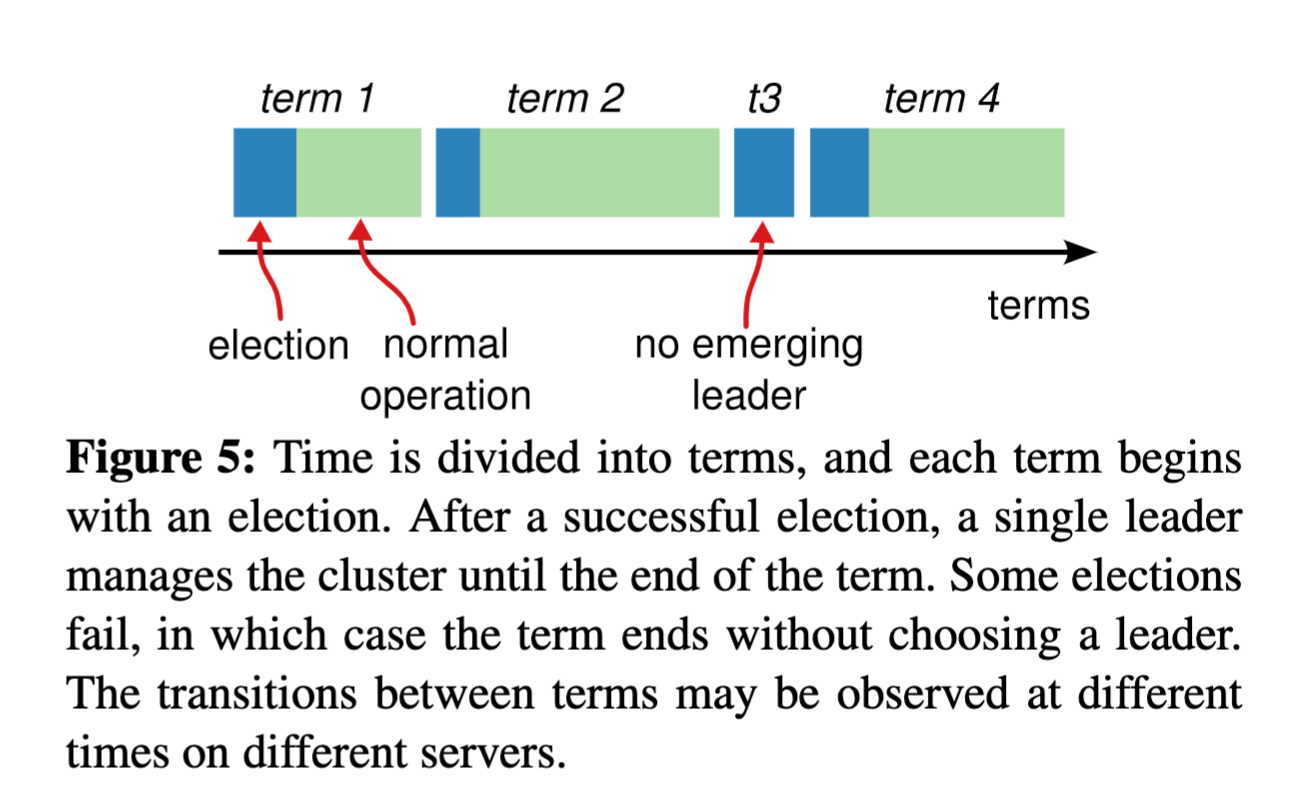
一个term一般包含两个阶段,选举阶段和统治阶段,当然如果没有选举成功,比如在集群扩容时产生的平票问题,则只有选举阶段。
在上面的图中,term1开始一次新选举,选举成功之后开始正常统治,term2和term1类似,term3则是选举失败,term4正常选举成功。term在Raft中起到了逻辑时钟的作用,它可以保障Raft在任意时刻只有一个Leader,特别是在集群成员变更的时候,比如上面的term3阶段,这个阶段没有Leader,集群不能对外界提供服务,由于各个节点设置的随机超时时间不一样,最先超时的Follower节点首先变为Candidate开始竞选Leader,竞选成功之后就是后面的term4阶段。
选举流程
Raft使用心跳机制来出发选举,Raft选举过程节点状态迁移图如下: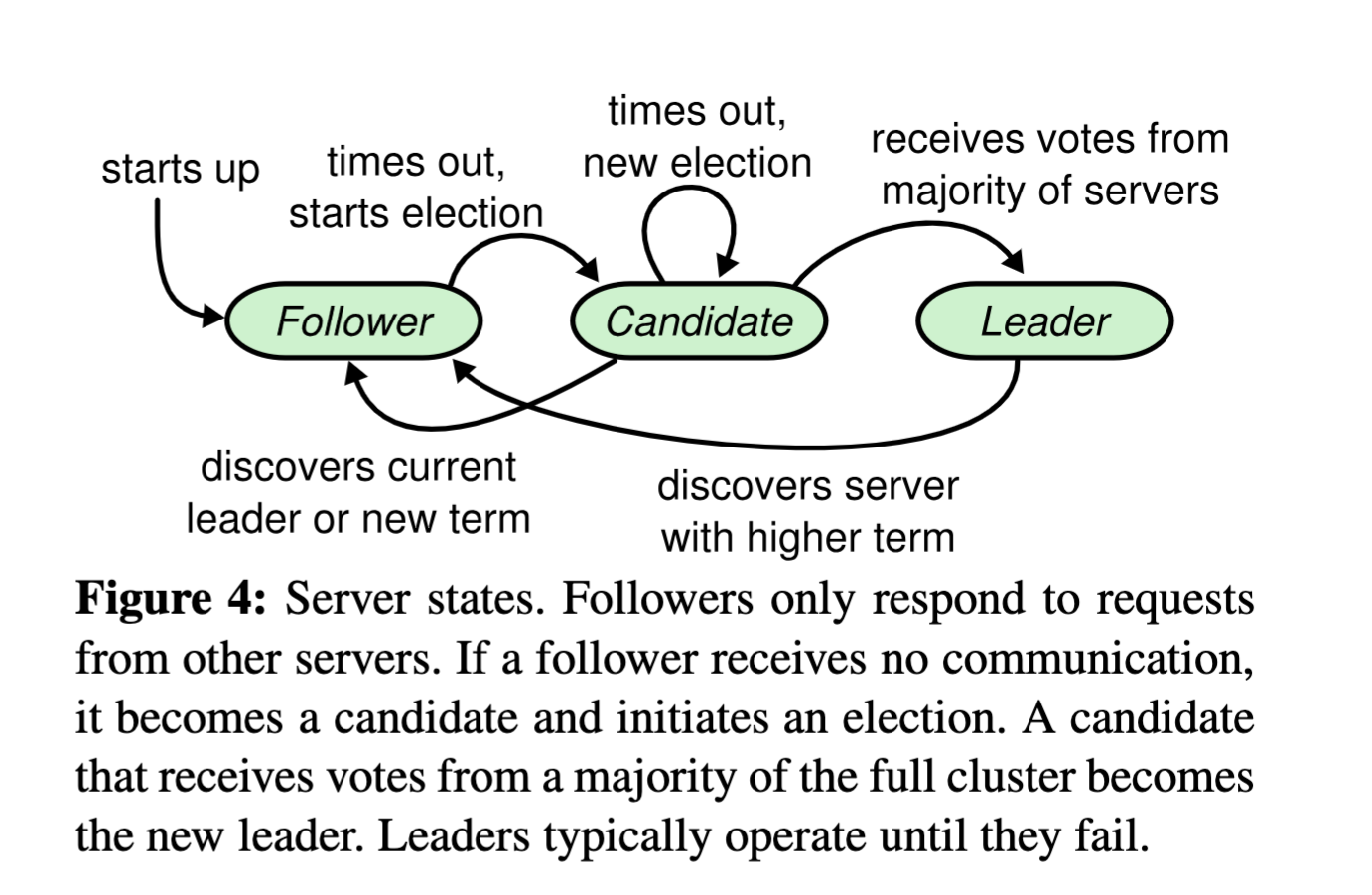
初始状态下所有节点都是Follower, 随机设定的选举时间超时之后,Follower变为Candidate,Candidate将自己的Term+1开始竞选Leader,向所有节点发送投票请求(RequestVote RPC),投票会有三种结果:
- 选举成功:如果Candidate获得大部分选票($N/2+1$),那么将从Candidate升级为Leader
- 选举失败:有两种情况会导致选举失败,1. 选举过程中发现其他Leader的心跳; 2. 投票请求响应的Term大于当前节点的Term则选举时候不到
- 选举超时:投票请求知道固定时间内没有收到其他节点的响应,或者收到了响应的节点数量没有大于$N/2+1$ ,那么选举就会超时,进入下一轮选举。
Leader在发现其他Server有更高的任期编号,则自动退回到Follower。
这个选举流程还是挺简单的,但是我们仍然会有疑问,节点的投票条件是什么?其实就一条:具备完备的 committed log(被多数节点接受并且持久化的的日志) 数据即可,有两种情况:
- 如果收到的请求投票消息的Term小于自己当前的Term,则拒绝投票。
- 如果收到的请求投票消息的Term大于自己当前的Term,则更新自己的Term为收到的Term,节点状态转变为Follower。
- 如果自己还没有投票或者已经投票给了当前的Candidate,且收到的请求投票消息的Last Log Index和Term都大于等于自己的Last Log Index和Term,则投赞成票。
- 如果收到的请求投票消息的Last Log Index和Term都小于自己的Last Log Index和Term,则拒绝投票。
当出现多个Candidate同时宣布自己是Leader时,由于选举过程中存在随机化的因素,可能会出现选平票的情况。在这种情况下,Raft算法规定如果两个Candidate的Term相同,那么选举将以最先收到选票的Candidate为准。其它候选者在接收到更高Term的选票后会立即转变为Follower,参与下一轮的选举。这样可以确保最终只有一个领导者被选举出来。


