
2025:平凡的一年
转眼间,已经2026年1月底,明天就是我的35岁生日,2025年度复盘的文档在年底都已建好,但是迟迟没有动笔,我当时给自己找到理由是:复盘太过于正式,会让自己形成表演人格,而我并不需要给任何人展示我的人生, 我很赞同某些人不写年终总结,他们有自己的复...
转眼间,已经2026年1月底,明天就是我的35岁生日,2025年度复盘的文档在年底都已建好,但是迟迟没有动笔,我当时给自己找到理由是:复盘太过于正式,会让自己形成表演人格,而我并不需要给任何人展示我的人生, 我很赞同某些人不写年终总结,他们有自己的复...
不知不觉马上就过 2025农历蛇年了,这篇年终总结也从 2024 年 12 月份开始要写的年终总结也一直拖到了现在(1 月 13 号),又拖到了今天发布,一直都在以各种借口拖延,加班很多,工作很「忙」,但是对我来说,「忙」也要抽出时间来做一个简短的总...
新公司入职有一段时间了,感觉是时候记录一下裁员的这段经历了,「裁员」在这个行业里应该是每个人都必须经历的事情,现在回想起来那一个多月真的是比较煎熬和恐惧。 2024年7月19日,体验了人生中的第一次裁员,现在所做的公司是一个跨境电商Farfetch,...
之前在Weread的Wiki中介绍过使用Dataview和Minimal主题管理微信读书的方法:使用Dataview进行书籍管理 ,随着Weread插件的不断迭代,现在增加了不少元数据,比如,开始阅读日期:readingDate,完成阅读日期:finishedDate ,阅读进度:progress等,且不需要手动添加readYear属性了,有了这些新的数据就可以更好的汇总读书数据了。 使用效果如图:
Background最近一段时间接手了几个Spark相关的大数据项目,主要使用Scala来编写代码,做了几个需求,感觉Scala这门语言还挺有意思,Scala以前也学习过,但是是很早了,很多语法点都忘了,在工作中经常编写的代码是Spark Job,使用stream的方式来编写代码,感觉非常的舒服。Spark中经常使用的一个操作是使用$来选择Column,比如下面使用$选择dt这一列,
磨刀不误砍柴工,输入法是平时使用频率极高的工具类软件,因此值得花时间去让这个工具变得更加趁手,在 2022 年我学会了双拼输入法(如果你还在使用全拼,我强烈建议学一下双拼,可以参考我之前写的这篇博客:也许你该试试双拼输入法 | Hank’s Blog
最近看了DDIA,对于分布式共识算法很感兴趣,可以说共识算法是分布式的基石,而 Raft 算法又是共识算法中最简单的一个,Raft算法是一个专门用于管理日志复制的共识算法。共识(consensus)是大家关心的某件事情(比如选举、分布式锁、全局ID、数据复制等等)达成一致的过程及其算法。 Raft算法诞生与2013年,论文名字叫作《In Search of an Understandable Consensus Algorithm》,寻找一个更加容易理解的共识算法,从名字就能看出来,作者对 Paxos 的绝望。
读完了《重来:更为简单有效的商业思维》这本小册子,最大的感受是,「生意再小也要有自己的事业」,且越早开始越好。 事业的可以从自己的「痒处」开始,也就是打造自己需要的产品,不一定是颠覆的产品,可以在现有的产品上进行微创新,但是至少一定解决了人的一些痛点或者痒点的产品。
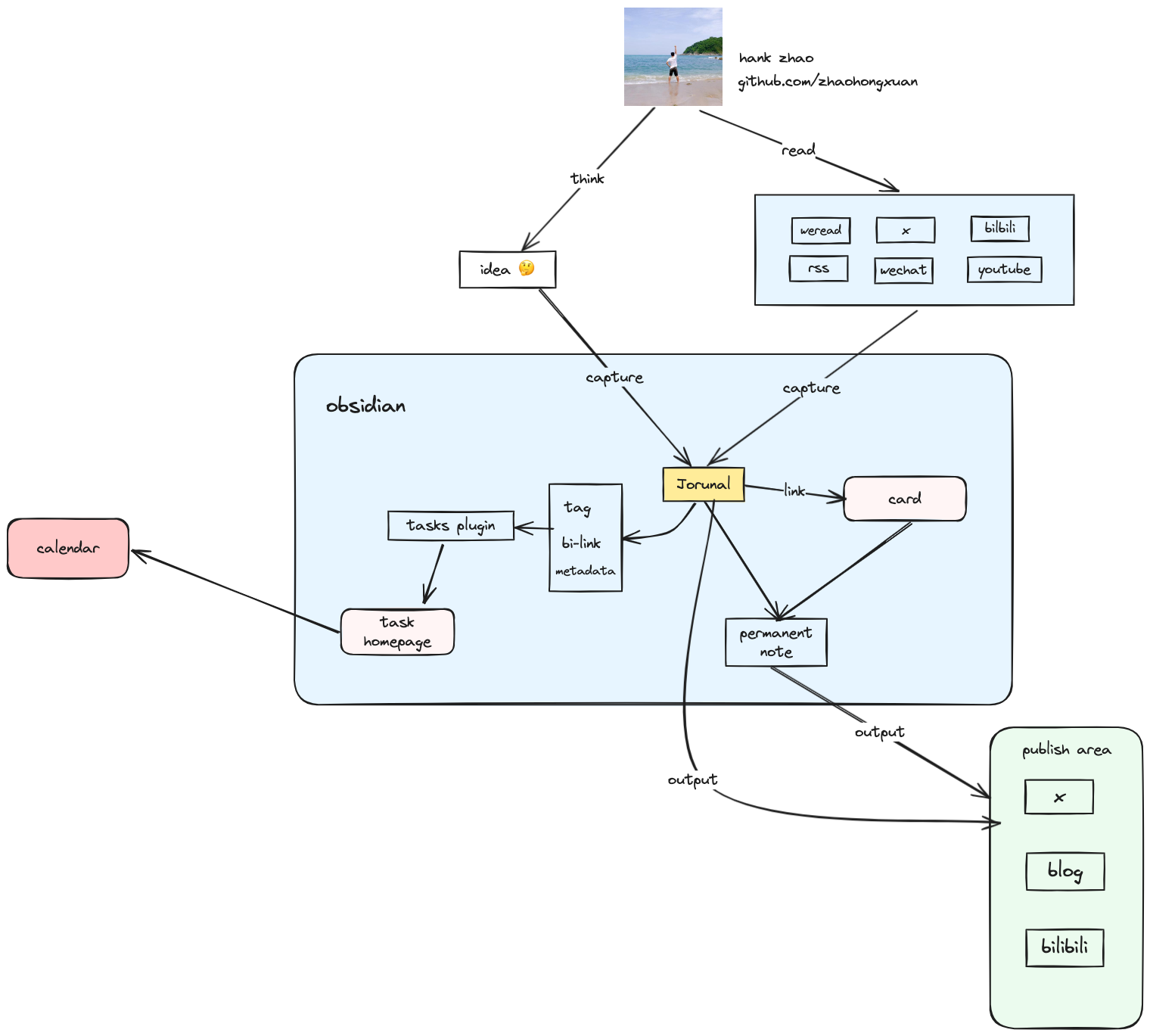
个人认为笔记的本质是: 让思考继续发生。记笔记不是目的,是为了更好的服务于思考,但是大脑不善于存储和检索,因此才要记笔记,本质是上是给大脑减压,记笔记的各种方法也都是为了让大脑更好的思考。大脑本能是躲避思考的,所以要尽可能简化记笔记的流程,形成习惯。 由于我对卡片笔记的理解还不够深刻,也还在探索中,因此这篇文章旨在分享我的一些心得和体会,每个人的习惯不一样,因此笔记方法因人而已,别人的方法不一定是适合自己的,每个人都要探索形成自己的笔记方法。 我的笔记原则
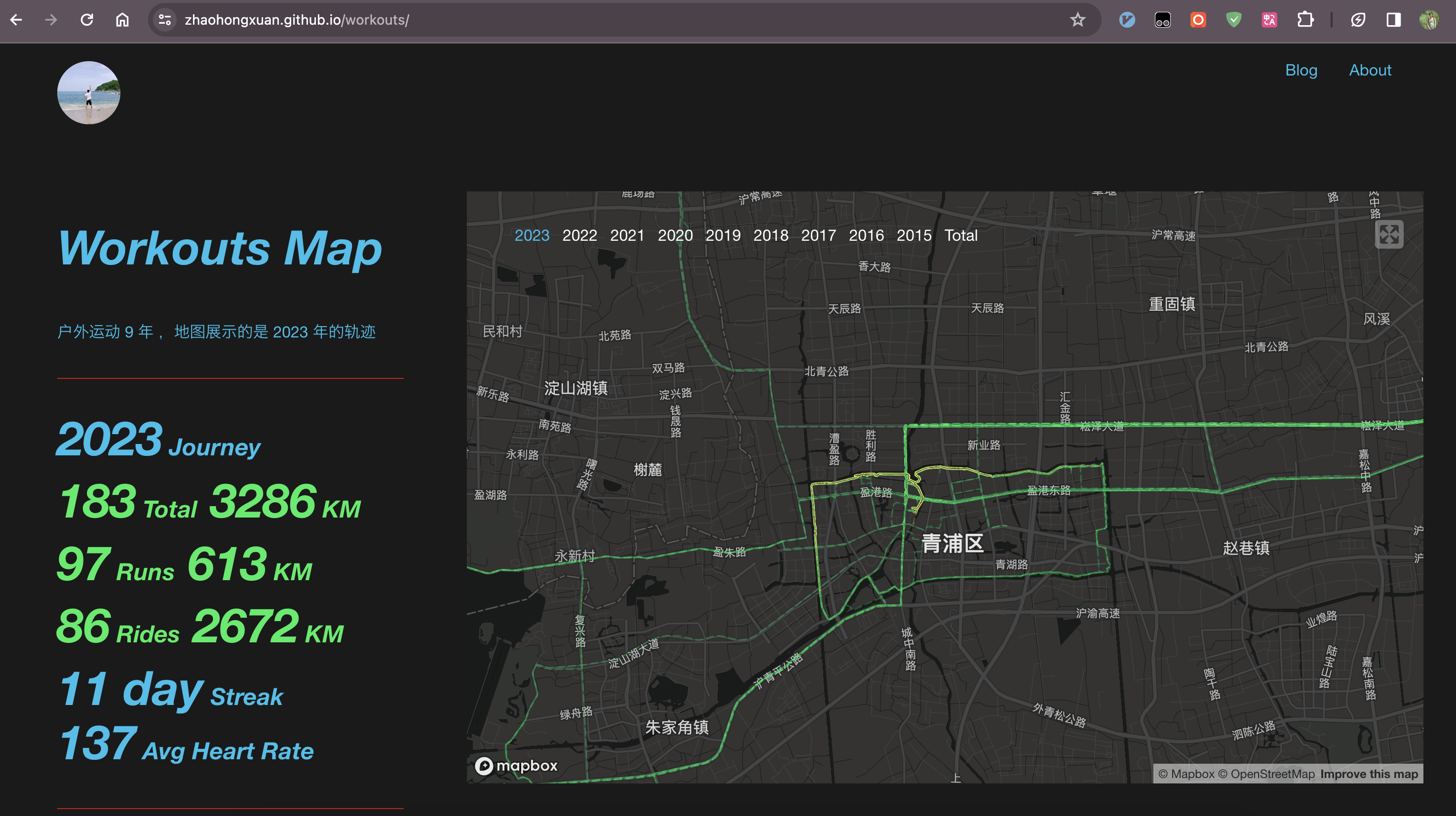
首先我要感谢这一年的自己,对自己说一声辛苦了。虽然这一年过得十分艰难,很多事情都发展不顺利,但是还是要对自己说一声辛苦了,最起码坚持到了最后,成功又度过了一年。 一些收获从2023年底到今年年初,主要是和同学一起翻译《Python for MATLAB Development》,人民邮电出版社引进的一本比较小众的技术书,出版社审核的时间有点长,不出意外的话,应该2024年第一季度会出版,这是我正式翻译的第一本书,难度确实不小,虽然现在各类翻译软件层出不穷,但是想要准确的翻译还是有不小的挑战的,里面的专业词汇有点多,长句也很多,花了将近半年才翻译完。