Kafka为什么这么快(吞吐性高)?
kafka作为一个处理实时数据和日志的管道,每秒可以处理几十万条消息,那么为什么Kafka的吞吐量这么高呢?
我们先来看一下Kafka的文件存储系统:
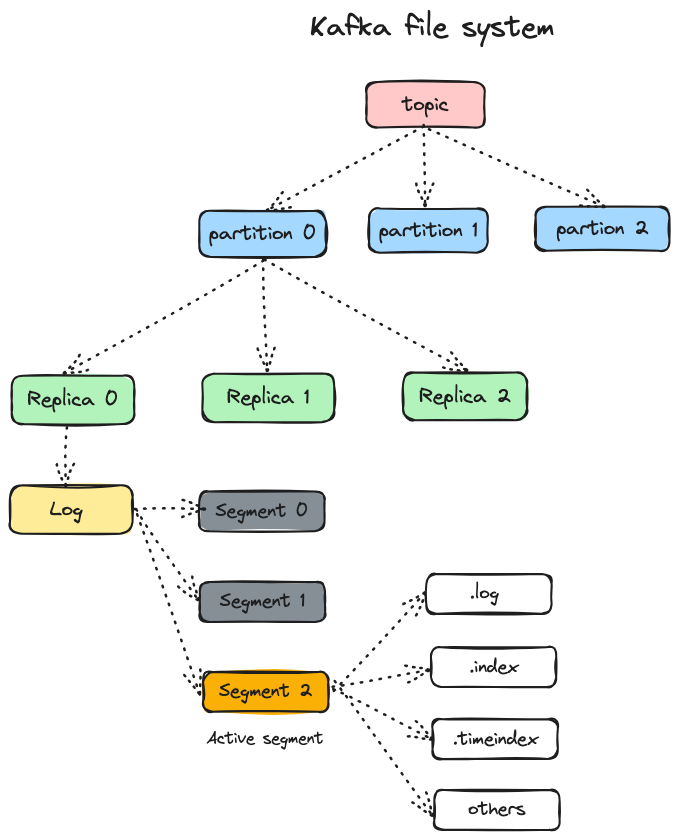
分区机制
Kafka中一个主题有多个Partition(分区),一个Topic可以横跨多个Broker。在生产消息时,因此在向Topic发送消息的时候将消息并发地写入到多个broker ,broker的数量可以横向扩展。
在消费消息时,引入了消费者群组(Consumer Group)的概念,一个分区只能被一个消费者群组中的的一个消费者消息,但是可以被其他群组的消费者消费,可以在一个消费组里起多个消费者,每个消费者消费一个分区,这样就提高了消费者的性能。需要注意的是,消费组里的消费者个数如果多于分区数的话,那些多出来的消费者就会处于空闲状态,所以一个消费组里的消费者个数跟分区数相等就好了。
分区的设计使得Kafka消息的读写性能可以突破单台broker的I/O性能瓶颈,可以在创建主题的时候指定分区数,也可以在主题创建完成之后去修改分区数,通过增加分区数可以实现水平扩展,但是要注意,分区数也不是越多越好,一般达到某一个阈值之后,再增加分区数性能反而会下降,具体阈值需要对Kafka集群进行压测才能确定。
日志分段存储
为了防止日志(Log)过大,Kafka引入了日志分段(LogSegment)的概念,将日志切分成多个日志分段。在磁盘上,日志是一个目录,每个日志分段对应于日志目录下的日志文件、偏移量索引文件、时间戳索引文件(可能还有其他文件)。
向日志中追加消息是顺序写入的,只有最后一个日志分段才能执行写入操作,之前所有的日志分段都不能写入数据。
为了便于检索,每个日志分段都有两个索引文件:==偏移量索引文件==和==时间戳索引文件==。每个日志分段都有一个基准偏移量baseOffset,用来表示当前日志分段中第一条消息的offset。偏移量索引文件和时间戳索引文件是以稀疏索引的方式构造的,偏移量索引文件中的偏移量和时间戳索引文件中的时间戳都是严格单调递增的。查询指定偏移量(或时间戳)时,使用二分查找快速定位到偏移量(或时间戳)的位置。可见Kafka中对消息的查找速度还是非常快的。
操作系统页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘I/O的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
Kafka中大量使用了页缓存,消息都是先被写入页缓存,再由操作系统负责具体的刷盘任务(Kafka中也提供了同步刷盘和异步刷盘的功能)
Kafka并不太依赖JVM内存大小,而是主要利用Page Cache,如果使用应用层缓存(JVM堆内存),会增加GC负担,增加停顿时间和延迟,创建对象的开销也会比较高。
读取操作可以直接在Page Cache上进行,如果消费和生产速度相当,甚至不需要通过物理磁盘直接交换数据,这是Kafka高吞吐量的一个重要原因。
这么做还有一个优势,如果Kafka重启,JVM内的Cache会失效,Page Cache依然可用。
磁盘顺序访问
Kafka的每条消息都是append的,不会从中间写入和删除消息,保证了磁盘的顺序访问,所以不管文件多大,写入总是O(1)的时间复杂度。减少频繁的小IO操作,Kafka的策略是把消息集合在一起,批量发送,尽可能减少对磁盘的访问。
批量操作
写入的时候放到RecordAccumulator进行聚合,批量压缩,还有批量刷盘等…
异步操作
异步操作可以在调用send方法后立即返回,等待buffer满了之后交给poll线程,发送消息、接收消息、复制数据也都是通过NetworkClient封装的poll的方式。
零拷贝
Kafka 使用零复制技术向客户端发送消息——也就是说,Kafka 直接把消 息从文件(或者更确切地说是 Linux 文件系统缓存)里发送到网络通道,而不需要经过任 何中间缓冲区。这是 Kafka 与其他大部分数据库系统不一样的地方,其他数据库在将数据 发送给客户端之前会先把它们保存在本地缓存里。这项技术避免了字节复制,也不需要管理内存缓冲区,从而获得更好的性能。
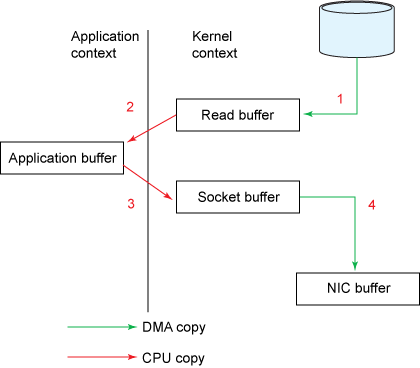
我们以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过Socket将内存中的数据发送出去。
伪代码如下:
1 | buffer = File.read |
这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态Buffer(DMA拷贝),然后应用程序将内存态Buffer数据读入到用户态Buffer(CPU拷贝),接着用户程序通过Socket发送数据时将用户态Buffer数据拷贝到内核态Buffer(CPU拷贝),最后通过DMA拷贝将数据拷贝到NIC Buffer。同时,还伴随着四次上下文切换。
sendfile和transferTo实现零拷贝
Linux 2.4+内核通过sendfile系统调用,提供了零拷贝。数据通过DMA拷贝到内核态Buffer后,直接通过DMA拷贝到NIC Buffer,无需CPU拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件-网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
具体实现上,Kafka的数据传输通过TransportLayer来完成,其子类PlaintextTransportLayer通过Java NIO的FileChannel的transferTo和transferFrom方法实现零拷贝。
数据压缩
Kafka使用端到端的块压缩功能。如果启用,数据将由producer压缩,以压缩格式写入服务器,并由 consumer 解压缩。压缩将提高 consumer 的吞吐量,但需付出一定的解压成本。这在跨数据中心镜像数据时尤其有用。
目前 Kafka 共支持四种主要的压缩类型:Gzip、Snappy、Lz4 和 Zstd。关于这几种压缩的特性,
| 压缩类型 | 压缩比率 | CPU 使用率 | 压缩速度 | 带宽使用率 |
|---|---|---|---|---|
| Gzip | Highest | Highest | Slowest | Lowest |
| Snappy | Medium | Moderate | Moderate | Medium |
| Lz4 | Low | Lowest | Fastest | Highest |
| Zstd | Medium | Moderate | Moderate | Medium |


